Markov Chains and Hidden Markov Models
Important citations: This post began with me taking notes on a series of videos by "Normalized Nerd" on Markov Chains in an effort to better understand the content from my robotics class. I infused some of my own intuition and notation, but a lot of the content comes directly from these two sources. All credit to them.
Markov Models
Say you have a restuarant which serves three foods: apples, sandwiches, and hamburgers. The food they serve on a particular day probabilistically depends on what was served the previous day. "Probabilistically" refers to the fact that, given we know what was served yesterday, we have a probability mass function of what was served today over the possible options. Observe a visual representation of such a system below:
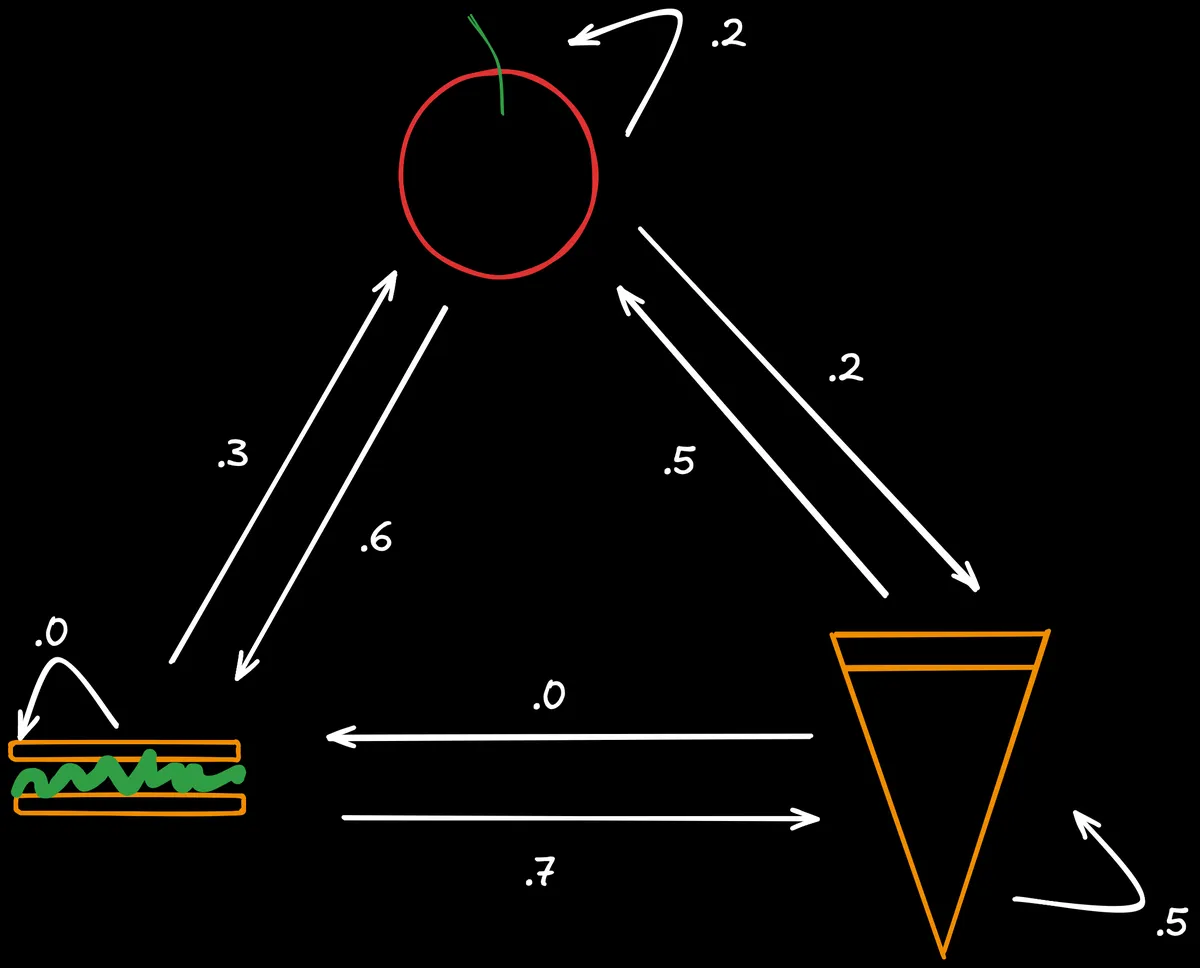
Notice that the sum of the outgoing edges for any given state is 1. In the context of a particular transition from one state to the next (outgoing edges), the sample space of possible events is only the three other states (). , or for short. I will denote the possible options for state with and the state at any particular time with .
Markov Assumption
The defining property of markov systems is that the state of the system only depends on the previous state and nothing else. Look back at the graph above -- what other information could we possibly have or need? This is known as the markov assumption or markov property, and it can be demonstrated mathematically as follows:
Now here's two thought-provoking questions: What would mean in isolation? More generally, what about the pmf of ?
Obviously, this quantity represents the probability of being in any particular state, but it is a bit tricky to think about obtaining this value. While determining these values mathematically will require some more background, I can say right now that it refers to the steady state probability. After we've served food for a long time (or taken a random walk along the Markov chain with an infinite number of steps), we can divide the occurences of one food over the total number of steps to get the probability for each food.
Before solving for these values, allow me to introduce some more notation.
import numpy as np
def random_walk(transition_matrix, start_state, n_steps):
states = [start_state]
current_state = start_state
for _ in range(n_steps):
current_state = np.random.choice(
len(transition_matrix),
p=transition_matrix[current_state]
)
states.append(current_state)
unique, counts = np.unique(states, return_counts=True)
pmf = np.zeros(len(transition_matrix))
pmf[unique] = counts / len(states)
return pmf
P = np.array([
[.2 , .6, .2],
[.3, .0, .7],
[.5, .0, .5]
])
random_walk(P, start_state=0, n_steps=1000000)
array([0.35187765, 0.21147579, 0.43664656])
Transition Matrix
A helpful way to represent the system is with a transition matrix:
Each row represents a particular current state and the values in that row are the probabilities of transitioning to that state in . Let the first value be apple, second sandwich, and third pizza. would refer to the probability of transitioning to state from , or . Once again, notice how the rows sum to one as expected. I like to think of like this:
Next, let be a column vector which refers to the pmf of states at time .
$\pi_t = \begin{pmatrix}
P(X_t=A)
P(X_t=S)
P(X_t=P)
\end{pmatrix}$
Imagine that we start on apple, so $\pi_0=\begin{pmatrix}
1
0
0
\end{pmatrix}$. How could we find $\pi_1$? It's easier to start by determining $\pi_1^1$ (also denoted as ) and then generalizing.
Applying the law of total probability:
We know from and from the first column of . Plugging in the values:
Generalizing this formula to the other possible states for :
This is equivalent to the following:
Notice that the i-th value is the dot product of the i-th column of with . This looks a lot like matrix-vector multiplication, except matrix-vector multiplication takes the dot product of the i-th row with the vector. So, we can just transpose and multiply that with to get !
Therefore, to find the pmf of the system, calculate .
import numpy as np
def steady_state(transition_matrix, start_state, n_steps):
current_state = np.zeros(len(transition_matrix))
current_state[start_state] = 1
transition_matrix_T = transition_matrix.T
for _ in range(n_steps):
current_state = transition_matrix_T @ current_state
return current_state.tolist()
P = np.array([
[.2 , .6, .2],
[.3, .0, .7],
[.5, .0, .5]
])
steady_state(P, start_state=0, n_steps=10000)
[0.352112676056338, 0.21126760563380279, 0.43661971830985913]
Even better, we don't even need to use the recursive formula. Check this out:
The two vectors are actually the same. This is exactly the eigenvalue equation you're familiar with (). Therefore, we can immediately determine the steady state probability distribution of the markov system by finding the left-eigenvector of or the right-eigenvector of for eigenvalue .
import numpy as np
def steady_state(transition_matrix):
transition_matrix_T = transition_matrix.T
eigenvalues, eigenvectors = np.linalg.eig(transition_matrix_T)
# Find index of eigenvalue closest to 1
stationary_idx = np.argmin(np.abs(eigenvalues - 1))
# Get corresponding eigenvector and normalize
stationary_dist = np.real(eigenvectors[:, stationary_idx])
return (stationary_dist / np.sum(stationary_dist)).tolist()
steady_state(P)
[0.35211267605633817, 0.21126760563380279, 0.4366197183098591]
Hidden Markov Models
In real world settings, we typically don't have the ability to directly measure the states we're interested in. Consider the problem of estimating the position of an autonomous car: we may receive odometry from SLAM, GPS, IMU, etc... but these measurements are noisy and do not truly reflect the state we want. The true position of the car is known as a hidden state, and the readings we get from our sensors and models are observations. A hidden markov model lets us use these readings to make predictions about the hidden state without direct access.
Imagine you are being held captive inside an office building with no windows. All day, you dream about the outside and desparetly want to know the weather (hidden state). The only weather-related information you have access to is the attire of the employees who come into the office every day. More specifically, you want to know if it's sunny or rainy based on if the employees bring umbrellas or are wearing shorts. Let be the hidden weather state where means it's rainy and means it's sunny. Let be the observed state where means people brought umbrellas and means poeple are wearing shorts.
The main idea is that, although we can't directly observe a hidden state, the observed state still gives us valuable information about the hidden state.
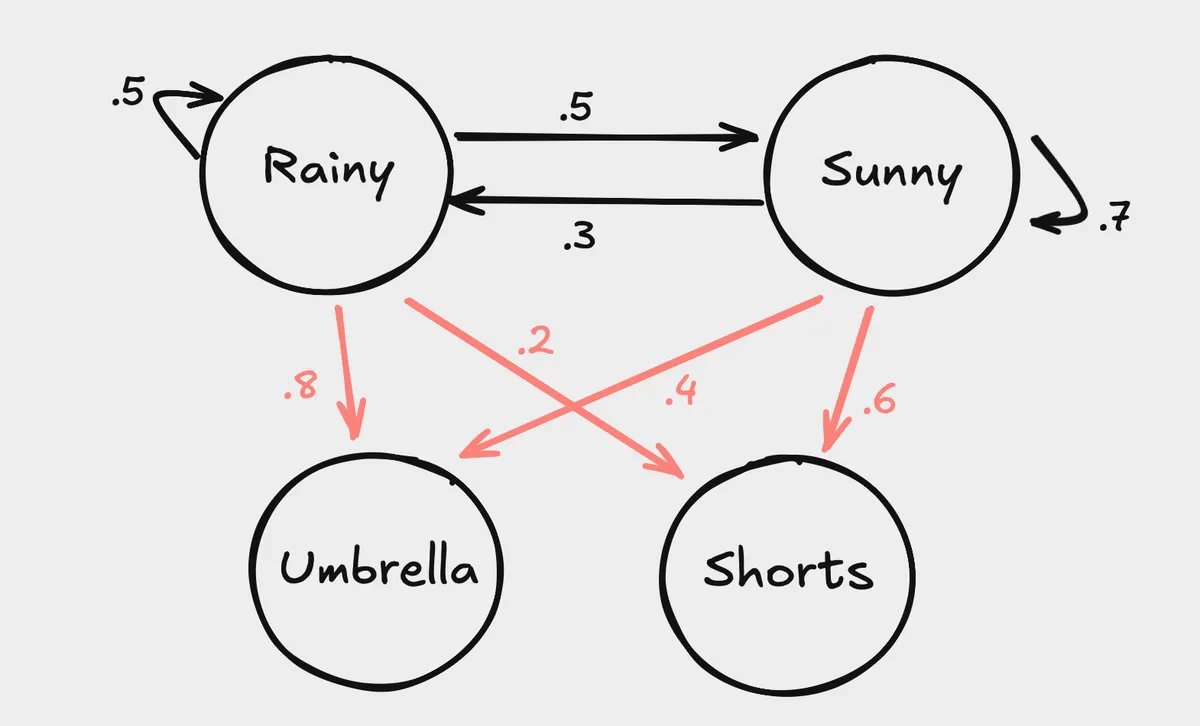 The arrows depicted in red correspond to condition probabilities of observed states based on hidden states. The probability that people bring umbrellas given that it's raining, or is . The transition matrix is the same as before:
The arrows depicted in red correspond to condition probabilities of observed states based on hidden states. The probability that people bring umbrellas given that it's raining, or is . The transition matrix is the same as before:
Emission Matrix
We need a way to represent the conditional probabilities in matrix form. From now on, these condition probabilities will be known as emission probabilties and the corresponding matrix is the emission matrix:
Keep in mind that this matrix doesn't have to be square. If we only wanted to estimate position based on three different sensors, our matrix would have 1 row and 3 columns.
HMMs allow us to solve a number of interesting problems in the real world.
- Filtering: Given observations up to time , compute the distribution of the state at time :
- Smoothing: Given observations up to time , compute the distribution of the state at any time :
Notice that this problem cannot be solved online because we don't have access to future observations.
- Prediction: Given observations up to time , compute the distribution of the state at a time :
- Decoding: Find the state trajectory that maximizes the probability given observations :
- Likelihood of observations: Given the observation trajectory, , compute the probability:
The likelihood appears in the denominator of Bayes Rule when trying to calculate .
Now, how might we determine ? Recall that, under the markov assumption, events at different timesteps are independent. Therefore, the probability can be simplified to the following:
And these values come directly from the emission matrix:
What if we wanted to calculate in this scenario? We'd have to include the probability of observing that particular sequence of hidden states too:
Recall that comes from the steady state distribution of the hidden states, so we have to calculate that using the eigenvalue method.
T = np.array([
[.5, .5,],
[.3, .7,],
])
random_walk(P)
[0.35211267605633817, 0.21126760563380279, 0.4366197183098591]
Now, a slightly more difficult question: What is ? Computing this would require us to perform the computation above but for all possible sequences of , which is (2 options, 3 positions). This is an application of the law of total probability.
Alternatively:
Now imagine the difficulty in computing this expression in real-time as the sequence length and number of states grows. It's intractable. Thankfully, we can take advantage of the fact that many values are being computed more than once. The forward algorithm defines a recurrence relation we can use as part of a memoization approach to avoid the repeated computations.
Forward Algorithm
Imagine that we knew the value of and . We could compute the likelihood for the sequence of observations by simply summing these values:
Let . We can then find the likelihood with the following formula, where represents the possible hidden states.
But how do we actually find ? This is where the recurrence comes in! For clarity, I'll first state the formula for a single timestep with the expanded version and then reintroduce alpha.
Now, in terms of :
And if we wanted to find or :
See how and reappear in both -- this is the key!
The base case of this recurrence relation is .
Finally, here is the general formula for the recurrence relation (with both and referring to hidden states):
Now I will carry out the forward algorithm of the HMM:
def steady_state(transition_matrix):
transition_matrix_T = transition_matrix.T
eigenvalues, eigenvectors = np.linalg.eig(transition_matrix_T)
stationary_idx = np.argmin(np.abs(eigenvalues - 1))
stationary_dist = np.real(eigenvectors[:, stationary_idx])
return stationary_dist / np.sum(stationary_dist)
T = np.array([[0.5, 0.5], [0.3, 0.7]])
M = np.array([[0.8, 0.2], [0.4, 0.6]])
pi = steady_state(T)
observations = [0, 0, 1]
n_hidden_states = len(T)
alphas = {'0': [], '1': []}
if observations:
first_obs = observations[0]
alphas['0'] = [pi[0] * M[0, first_obs]]
alphas['1'] = [pi[1] * M[1, first_obs]]
for t in range(1, len(observations)):
current_obs = observations[t]
new_alpha_0 = (alphas['0'][t-1] * T[0, 0] + alphas['1'][t-1] * T[1, 0]) * M[0, current_obs]
new_alpha_1 = (alphas['0'][t-1] * T[0, 1] + alphas['1'][t-1] * T[1, 1]) * M[1, current_obs]
alphas['0'].append(new_alpha_0)
alphas['1'].append(new_alpha_1)
print("Alphas after correction:", sum([alpha[-1] for alpha in alphas.values()]))
Alphas after correction: 0.13440000000000002
import numpy as np
def forward_algorithm(transition_matrix, emission_matrix, initial_dist, observations):
n_states = transition_matrix.shape[0]
n_obs = len(observations)
alphas = np.zeros((n_states, n_obs))
first_obs = observations[0]
alphas[:, 0] = initial_dist * emission_matrix[:, first_obs]
for t in range(1, n_obs):
current_obs = observations[t]
alphas[:, t] = emission_matrix[:, current_obs] * (alphas[:, t-1] @ transition_matrix)
total_prob = np.sum(alphas[:, -1])
return alphas.tolist(), total_prob.tolist()
def steady_state(transition_matrix):
transition_matrix_T = transition_matrix.T
eigenvalues, eigenvectors = np.linalg.eig(transition_matrix_T)
stationary_idx = np.argmin(np.abs(eigenvalues - 1))
stationary_dist = np.real(eigenvectors[:, stationary_idx])
return stationary_dist / np.sum(stationary_dist)
T = np.array([[0.5, 0.5], [0.3, 0.7]])
M = np.array([[0.8, 0.2], [0.4, 0.6]])
pi = steady_state(T)
observations = [0, 0, 1]
alphas, total_prob = forward_algorithm(T, M, pi, observations)
print(" Timestep: 0 1 2")
for i, alpha in enumerate(alphas):
print(f"Alpha for hidden state {i}:", [round(a_t,4) for a_t in alpha])
print("Total probability of observations:", round(total_prob,4))
Timestep: 0 1 2
Alpha for hidden state 0: [0.3, 0.18, 0.0258]
Alpha for hidden state 1: [0.25, 0.13, 0.1086]
Total probability of observations: 0.1344
Backward Algorithm
To perform algorithms like decoding or smoothing, there's another probability for which we have to define a recursive algorithm: . The forward algorithm lets us efficiently calculate the probability of arriving at state and emitting observation sequence from the start to . The backward lets us efficiently calculate the probability of emitting the rest of the observation sequence from to the end given we were at state .
This formulation makes the calculation for smoothing very simple. To calculate using and , we can perform the following derivation:
Recall that the rule which lets us split into the expanded form is simply the chain rule of probability: . Next, we use the assumption that observations are independent to simplify the conditional.
With that justification, it's time to derive the backward algorithm:
Firstly, for all hidden states because there is no to compute.
Now for earlier states , we can compute in the following way:
This lets us compute the likelihood:
import numpy as np
def forward_algorithm(transition_matrix, emission_matrix, initial_dist, observations):
n_states = transition_matrix.shape[0]
n_obs = len(observations)
alphas = np.zeros((n_states, n_obs))
first_obs = observations[0]
alphas[:, 0] = initial_dist * emission_matrix[:, first_obs]
for t in range(1, n_obs):
current_obs = observations[t]
alphas[:, t] = emission_matrix[:, current_obs] * (alphas[:, t-1] @ transition_matrix)
total_prob = np.sum(alphas[:, -1])
return alphas, total_prob
def backward_algorithm(transition_matrix, emission_matrix, initial_dist, observations):
n_states = transition_matrix.shape[0]
n_obs = len(observations)
betas = np.ones((n_states, n_obs))
for t in range(n_obs-2, -1, -1):
current_obs = observations[t+1]
betas[:, t] = (transition_matrix @ (emission_matrix[:, current_obs] * betas[:, t+1]))
first_obs = observations[0]
total_prob = np.sum(initial_dist * emission_matrix[:, first_obs] * betas[:, 0])
return betas, total_prob
def filtering_pmfs(alphas):
return alphas / np.sum(alphas, axis=0, keepdims=True)
def smoothing_pmfs(alphas, betas, total_prob):
return (alphas * betas)/ (total_prob + 1e-10) # Add small epsilon to avoid division by zero
T = np.array([[.1, .4, .5], [.4, .0, .6], [.0, .6, .4]])
M = np.array([[.6, .2, .2], [.2, .6, .2], [.2, .2, .6]])
pi = np.array([1., 0., 0.])
observations = [0, 2, 2]
alphas, f_prob = forward_algorithm(T, M, pi, observations)
betas, b_prob = backward_algorithm(T, M, pi, observations)
filtering = filtering_pmfs(alphas)
smoothing = smoothing_pmfs(alphas, betas, f_prob)
print("Forward Variables (α):")
print(np.round(alphas, 5))
print("\nBackward Variables (β):")
print(np.round(betas, 5))
print("\nFiltering PMFs:")
print(np.round(filtering, 4))
print("\nSmoothing PMFs:")
print(np.round(smoothing, 4))
print("\nTotal Probability (Forward):", round(f_prob, 5))
print("Total Probability (Backward):", round(b_prob, 5))
Forward Variables (α):
[[0.6 0.012 0.00408]
[0. 0.048 0.02256]
[0. 0.18 0.06408]]
Backward Variables (β):
[[0.1512 0.4 1. ]
[0.1616 0.44 1. ]
[0.1392 0.36 1. ]]
Filtering PMFs:
[[1. 0.05 0.045 ]
[0. 0.2 0.2487]
[0. 0.75 0.7063]]
Smoothing PMFs:
[[1. 0.0529 0.045 ]
[0. 0.2328 0.2487]
[0. 0.7143 0.7063]]
Total Probability (Forward): 0.09072
Total Probability (Backward): 0.09072
import numpy as np
def forward_algorithm(transition_matrix, emission_matrix, initial_dist, observations):
n_states = transition_matrix.shape[0]
n_obs = len(observations)
alphas = np.zeros((n_states, n_obs))
first_obs = observations[0]
alphas[:, 0] = initial_dist * emission_matrix[:, first_obs]
for t in range(1, n_obs):
current_obs = observations[t]
alphas[:, t] = emission_matrix[:, current_obs] * (alphas[:, t-1] @ transition_matrix)
total_prob = np.sum(alphas[:, -1])
return alphas, total_prob
def backward_algorithm(transition_matrix, emission_matrix, initial_dist, observations):
n_states = transition_matrix.shape[0]
n_obs = len(observations)
betas = np.ones((n_states, n_obs))
for t in range(n_obs-2, -1, -1):
current_obs = observations[t+1]
betas[:, t] = (transition_matrix @ (emission_matrix[:, current_obs] * betas[:, t+1]))
first_obs = observations[0]
total_prob = np.sum(initial_dist * emission_matrix[:, first_obs] * betas[:, 0])
return betas, total_prob
def filtering_pmfs(alphas):
return alphas / np.sum(alphas, axis=0, keepdims=True)
def smoothing_pmfs(alphas, betas, total_prob):
return (alphas * betas)/ (total_prob + 1e-10) # Add small epsilon to avoid division by zero
T = np.array([[.0, .5, .5], [.0, .9, .1], [.0, .0, 1.0]])
M = np.array([[0, .5, .5], [0, .9, .1], [0, .1, .9]])
pi = np.array([1., 0., 0.])
observations = [1,2,2,1,1,1,2,1,2]
alphas, f_prob = forward_algorithm(T, M, pi, observations)
betas, b_prob = backward_algorithm(T, M, pi, observations)
filtering = filtering_pmfs(alphas)
smoothing = smoothing_pmfs(alphas, betas, f_prob)
filtering_estimates = np.argmax(filtering, axis=0)
smoothing_estimates = np.argmax(smoothing, axis=0)
print("\nFiltering PMFs:")
print(np.round(filtering, 4))
print("\nSmoothing PMFs:")
print(np.round(smoothing, 4))
print("\nFiltering Estimates:")
print(filtering_estimates)
print("\nSmoothing Estimates:")
print(smoothing_estimates)
Filtering PMFs:
[[1. 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0.1 0.0109 0.0817 0.4165 0.8437 0.2595 0.7328 0.1771]
[0. 0.9 0.9891 0.9183 0.5835 0.1563 0.7405 0.2672 0.8229]]
Smoothing PMFs:
[[1. 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0.6297 0.6255 0.6251 0.6218 0.5948 0.3761 0.3543 0.1771]
[0. 0.3703 0.3744 0.3749 0.3782 0.4052 0.6239 0.6457 0.8229]]
Filtering Estimates:
[0 2 2 2 2 1 2 1 2]
Smoothing Estimates:
[0 1 1 1 1 1 2 2 2]
As you can tell, including the smoothing estimates prohibits the impossible trajectory , leading to a better result. Viterbi's algorithm gives a better method for computing the most likely trajectory, instead of a simpler point-wise estimate. I won't cover it here, but it's very similar to the forward-backward algorithm.
And that concludes this post on Markov Chains.